


Why should I use PySpark?
Business requirement
There are data coming to my system from multiple sources MySQL,SQL,Oracle, logs and including occasional files uploads.
The data comes both static and dynamic way i.e. real-time data as well as batch data.
I have to build a system which combines all these data inputs and prepares analytics over it.
PySpark is just a Python wrapper around Apache Spark which is written in Scala programming language. Why should I use PySpark instead of Pandas, Hadoop or Dask?

Pandas is good for : Tabular data with millions of rows
Limitation 1-5GB chunksize 5-30 GB
Technically the number of rows read at a time in a file by pandas is referred to as chunksize.
But, where does Pandas give up?
My data is stored across several computers in a distributed manner
My computer does not have the processing capability to process large amounts of data using Pandas.
My data comes in real time streaming way and as well as batches. I have to analytics by combining
In these cases, we have to look away from Pandas. My favorite Pandas is not enough for my increasing size and type of data.

Dask provides advanced parallelism for analytics, enabling performance at scale for the tools. It is written in Python on top of Pandas. Therefore, in addition to the features supported by Pandas it
lightweight and can run on both single and distributed cluster.
Dask provides parallel arrays, dataframes, machine learning, and custom algorithms which are easier to integrate with existing Python code.
Dask acts better in time series, random access, and other complex computations than Spark.
However, it has some limitations as well:
It has not implemented all the functionalities of Pandas.
Can not integrate with Hadoop, no wrapper yet with non-python languages.
It has fewer features than PySpark.
Limitation 30-100GB chunksize 200GB

I googled and found Hadoop is a well-established tool to handle my increasing growth of data. Few things which Hadoop is good for:
It’s a big data platform; distributed system
Hadoop has compute system, MapReduce and storage system, HDFS.
Can work by integrating cheap commodities together
Hadoop stores the incoming data in its HDFS system which is good for latency. However, its performance is not par with Spark, which stores data in memory. Therefore, Spark is faster than Hadoop. That makes the on-prem Spark deployment costly also.
In another case, HDFS recommends a file size of 128MB to store data at a time. Smaller units of data with repetitive write operation are not efficient, which affects my real-time data processing requirement.

It is a tough decision to choose in between Dask and PySpark. However, In addition to other differences, PySpark is an all-in-one ecosystem which can handle the aggressive requirements with its MLlib, Structured data processing API, GraphX will definitely of help.
Hadoop data can be processed with PySpark, so it will not be of any problem.
Limitation 1000GB -1TB 1000TB - 1PB
Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Ease of Use
Write applications quickly in Java, Scala, Python, R.
Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning,
GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including
HDFS, Cassandra, HBase, and S3.
Use Cases of ‘Spark with Python’ in Industries

Use cases of spark in other industries
Finance: PySpark is used in this sector as it helps gain insights from call recordings, emails, and social media profiles.
E-commerce: Apache Spark with Python can be used in this sector for gaining insights into real-time transactions. It can also be used to enhance recommendations to users based on new trends.
Healthcare: Apache Spark is being used to analyze patients’ medical records, along with the past medical history, and then make predictions on the most likely health issues those patients might face in the future.
Media: An example of this is Yahoo. Spark is being used at Yahoo to design its news pages for the targeted audience using Machine Learning features provided by Spark.
You have almost come to the end of this tutorial on ‘What is PySpark?’ Now, just check out the recommended audience at whom this tutorial is targeted.
Why Spark with Python (PySpark)?
No matter you like it or not, Python has been one of the most popular programming languages.


Before diving deep into how Apache Spark works, lets understand the jargon of Apache Spark
• Job: A piece of code which reads some input from HDFS or local, performs some computation on the
data and writes some output data.
• Stages: Jobs are divided into stages. Stages are classified as a Map or reduce stages (Its easier to
understand if you have worked on Hadoop and want to correlate). Stages are divided based on computational
boundaries, all computations (operators) cannot be Updated in a single Stage. It happens
over many stages.
• Tasks: Each stage has some tasks, one task per partition. One task is executed on one partition of data
on one executor (machine).
• DAG: DAG stands for Directed Acyclic Graph, in the present context its a DAG of operators.
• Executor: The process responsible for executing a task.
• Master: The machine on which the Driver program runs
• Slave: The machine on which the Executor program runs


1.Spark Driver
• separate process to execute user applications
• creates SparkContext to schedule jobs execution and negotiate with cluster manager
2. Executors
• run tasks scheduled by driver
• store computation results in memory, on disk or off-heap
• interact with storage systems
3. Cluster Manager
• Mesos
• YARN


Spark Standalone
Spark Driver contains more components responsible for translation of user code into actual jobs executed
on cluster:
• SparkContext
– represents the connection to a Spark cluster, and can be used to create RDDs, accumulators
and broadcast variables on that cluster
• DAGScheduler
– computes a DAG of stages for each job and submits them to TaskScheduler determines
preferred locations for tasks (based on cache status or shuffle files locations)
and finds minimum schedule to run the jobs
• TaskScheduler
– responsible for sending tasks to the cluster, running them, retrying if there are failures,
and mitigating stragglers
• SchedulerBackend
– backend interface for scheduling systems that allows plugging in different implementations(
Mesos, YARN, Standalone, local)
• BlockManager
– provides interfaces for putting and retrieving blocks both locally and remotely into
various stores (memory, disk, and off-heap)


The first layer is the interpreter, Spark uses a Scala interpreter, with some modifications. As you enter
your code in spark console (creating RDD’s and applying operators), Spark creates a operator graph. When
the user runs an action (like collect), the Graph is submitted to a DAG Scheduler. The DAG scheduler
divides operator graph into (map and reduce) stages. A stage is comprised of tasks based on partitions of
the input data. The DAG scheduler pipelines operators together to optimize the graph. For e.g. Many map
operators can be scheduled in a single stage. This optimization is key to Sparks performance. The final
result of a DAG scheduler is a set of stages. The stages are passed on to the Task Scheduler. The task
scheduler launches tasks via cluster manager. (Spark Standalone/Yarn/Mesos). The task scheduler doesn’t
know about dependencies among stages.
Colaboratory is a free Jupyter notebook environment that requires no setup and runs entirely in the cloud.
Installation
!pip install pyspark
Testing
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
df = spark.sparkContext\
.parallelize([(1, 2, 3, 'a b c'),
(4, 5, 6, 'd e f'),
(7, 8, 9, 'g h i')])\
.toDF(['col1', 'col2', 'col3','col4'])
df.show()

RDD represents Resilient Distributed Dataset. An RDD in Spark is simply an immutable distributed
collection of objects sets. Each RDD is split into multiple partitions (similar pattern with smaller sets),
which may be computed on different nodes of the cluster.
Usually, there are two popular ways to create the RDDs: loading an external dataset, or distributing a
set of collection of objects. The following examples show some simplest ways to create RDDs by using
parallelize() fucntion which takes an already existing collection in your program and pass the same
to the Spark Context.
By using parallelize( ) function
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
df = spark.sparkContext.parallelize([(1, 2, 3, 'a b c'),
(4, 5, 6, 'd e f'),
(7, 8, 9, 'g h i')]).toDF(['col1', 'col2', 'col3','col4'])
Then you will get the RDD data:
df.show()
By using createDataFrame( ) function
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Employee = spark.createDataFrame([
('1', 'Joe', '70000', '1'),
('2', 'Henry', '80000', '2'),
('3', 'Sam', '60000', '2'),
('4', 'Max', '90000', '1')],
['Id', 'Name', 'Sallary','DepartmentId']
)
Read dataset from .csv file
## set up SparkSession
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
df = spark.read.format('com.databricks.spark.csv').\
options(header='true', \
inferschema='true').\
load("/home/feng/Spark/Code/data/Advertising.csv",
˓→header=True)
df.show(5)
df.printSchema()
## set up SparkSession
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("pyarungupta") \
.config("spark.some.config.option", "some-value") \
(continues on next
.getOrCreate()
## User information
user = 'your_username'
pw = 'your_password'
## Database information
table_name = 'table_name'
url = 'jdbc:postgresql://##.###.###.##:5432/dataset?user='+user+'&
˓→password='+pw
properties ={'driver': 'org.postgresql.Driver', 'password': pw,'user
˓→': user}
df = spark.read.jdbc(url=url, table=table_name,
˓→properties=properties)
df.show(5)
df.printSchema()
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
from pyspark.sql import HiveContext
sc= SparkContext('local','example')
hc = HiveContext(sc)
tf1 = sc.textFile("hdfs://cdhstltest/user/data/demo.CSV")
print(tf1.first())
hc.sql("use intg_cme_w")
spf = hc.sql("SELECT * FROM spf LIMIT 100")
print(spf.show(5))


Once created, RDDs offer two types of operations: transformations and actions.
## set up SparkSession
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("https://pyarungupta.blogspot.com/2022/01/pyspark.html") \
.config("spark.some.config.option", "some-value") \
Transformations construct a new RDD from a previous one. For example, one common transformation is
filtering data that matches a predicate.
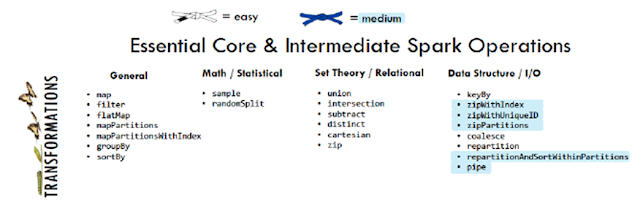


Actions, on the other hand, compute a result based on an RDD, and either return it to the driver program or
save it to an external storage system (e.g., HDFS).


Create DataFrame
1. From List
my_list = [['a', 1, 2], ['b', 2, 3],['c', 3, 4]]
col_name = ['A', 'B', 'C']
Python Code:
# caution for the columns=
pd.DataFrame(my_list,columns= col_name)
#
spark.createDataFrame(my_list, col_name).show()
Most of time, you need to share your code with your colleagues or release your code for Code Review or
Quality assurance(QA). You will definitely do not want to have your User Information in the code.
So you can save them in login.txt:runawayhorse001
PythonTips
and use the following code to import your User Information:
#User Information
try:
login = pd.read_csv(r'login.txt', header=None)
user = login[0][0]
pw = login[0][1]
print('User information is ready!')
except:
print('Login information is not available!!!')
#Database information
host = '##.###.###.##'
db_name = 'db_name'
table_name = 'table_name'

Data from: http://api.luftdaten.info/static/v1/data.json
dp = pd.read_json("data/data.json")
ds = spark.read.json('data/data.json')
:: Python Code:
dp[['id','timestamp']].head(4)
#
ds[['id','timestamp']].show(4)
First n Rows
:: Python Code:
dp.head(4)
#
ds.show(4)
Python Code:
dp.columns
#
ds.columns
Index(['TV', 'Radio', 'Newspaper', 'Sales'], dtype='object')
['TV', 'Radio', 'Newspaper', 'Sales']

:: Python Code:
dp.dtypes
#
ds.dtypes
:: Comparison:
TV float64 [('TV', 'double'),
Radio float64 ('Radio', 'double'),
Newspaper float64 ('Newspaper', 'double'),
Sales float64

my_list = [['male', 1, None], ['female', 2, 3],['male', 3, 4]]
dp = pd.DataFrame(my_list,columns=['A', 'B', 'C'])
ds = spark.createDataFrame(my_list, ['A', 'B', 'C'])
#
dp.head()
ds.show()
:: Python Code:
# caution: you need to chose specific col
dp.A.replace(['male', 'female'],[1, 0], inplace=True)
dp
#caution: Mixed type replacements are not supported
ds.na.replace(['male','female'],['1','0']).show()
1. Rename all columns
:: Python Code:
dp.columns = ['a','b','c','d']
dp.head(4)
#
ds.toDF('a','b','c','d').show(4)
mapping = {'Newspaper':'C','Sales':'D'}
:: Python Code:
dp.rename(columns=mapping).head(4)
#
new_names = [mapping.get(col,col) for col in ds.columns]
ds.toDF(*new_names).show(4)
Note: You can also use withColumnRenamed to rename one column in PySpark.
:: Python Code:
ds.withColumnRenamed('Newspaper','Paper').show(4)

dp = pd.read_csv('Advertising.csv')
#
ds = spark.read.csv(path='Advertising.csv',
header=True,
inferSchema=True)
:: Python Code:
dp[dp.Newspaper<20].head(4)
#
ds[ds.Newspaper<20].show(4)
dp[(dp.Newspaper<20)&(dp.TV>100)].head(4)
#
ds[(ds.Newspaper<20)&(ds.TV>100)].show(4)
drop_name = ['Newspaper','Sales']
:: Python Code:
dp.drop(drop_name,axis=1).head(4)
#
ds.drop(*drop_name).show(4)
:: Python Code:
dp['tv_norm'] = dp.TV/sum(dp.TV)
dp.head(4)
#
ds.withColumn('tv_norm', ds.TV/ds.groupBy().agg(F.sum("TV")).collect()[0][0]).
˓→show(4)
dp['cond'] = dp.apply(lambda c: 1 if ((c.TV>100)&(c.Radio<40)) else 2 if c.
˓→Sales> 10 else 3,axis=1)
#
ds.withColumn('cond',F.when((ds.TV>100)&(ds.Radio<40),1)\
.when(ds.Sales>10, 2)\
.otherwise(3)).show(4)
dp['log_tv'] = np.log(dp.TV)
dp.head(4)
#
import pyspark.sql.functions as F
ds.withColumn('log_tv',F.log(ds.TV)).show(4)
dp['tv+10'] = dp.TV.apply(lambda x: x+10)
dp.head(4)
#
ds.withColumn('tv+10', ds.TV+10).show(4)

leftp = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
rightp = pd.DataFrame({'A': ['A0', 'A1', 'A6', 'A7'],
'F': ['B4', 'B5', 'B6', 'B7'],
'G': ['C4', 'C5', 'C6', 'C7'],
'H': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
lefts = spark.createDataFrame(leftp)
rights = spark.createDataFrame(rightp)

:: Python Code:
leftp.merge(rightp,on='A',how='left')
#
lefts.join(rights,on='A',how='left')
.orderBy('A',ascending=True).show()
Right Join
:: Python Code:
leftp.merge(rightp,on='A',how='right')
#
lefts.join(rights,on='A',how='right')
.orderBy('A',ascending=True).show()
Inner Join
:: Python Code:
leftp.merge(rightp,on='A',how='inner')
#
lefts.join(rights,on='A',how='inner')
.orderBy('A',ascending=True).show()
Full Join
:: Python Code:
leftp.merge(rightp,on='A',how='outer')
#
lefts.join(rights,on='A',how='full')
.orderBy('A',ascending=True).show()
my_list = [('a', 2, 3),
('b', 5, 6),
('c', 8, 9),
('a', 2, 3),
('b', 5, 6),
('c', 8, 9)]
col_name = ['col1', 'col2', 'col3']
#
dp = pd.DataFrame(my_list,columns=col_name)
ds = spark.createDataFrame(my_list,schema=col_name)
:: Python Code:
dp['concat'] = dp.apply(lambda x:'%s%s'%(x['col1'],x['col2']),axis=1)
dp
#
ds.withColumn('concat',F.concat('col1','col2')).show()

:: Python Code:
dp.groupby(['col1']).agg({'col2':'min','col3':'mean'})
#
ds.groupBy(['col1']).agg({'col2': 'min', 'col3': 'avg'}).show()

:: Python Code:
pd.pivot_table(dp, values='col3', index='col1', columns='col2', aggfunc=np.
˓→sum)
#
ds.groupBy(['col1']).pivot('col2').sum('col3').show()

d = {'A':['a','b','c','d'],'B':['m','m','n','n'],'C':[1,2,3,6]}
dp = pd.DataFrame(d)
ds = spark.createDataFrame(dp)
:: Python Code:
dp['rank'] = dp.groupby('B')['C'].rank('dense',ascending=False)
#
from pyspark.sql.window import Window
w = Window.partitionBy('B').orderBy(ds.C.desc())
ds = ds.withColumn('rank',F.rank().over(w))
d ={'Id':[1,2,3,4,5,6],
'Score': [4.00, 4.00, 3.85, 3.65, 3.65, 3.50]}
#
data = pd.DataFrame(d)
dp = data.copy()
ds = spark.createDataFrame(data)
Python Code:
dp['Rank_dense'] = dp['Score'].rank(method='dense',ascending =False)
dp['Rank'] = dp['Score'].rank(method='min',ascending =False)
dp
#
import pyspark.sql.functions as F
from pyspark.sql.window import Window
w = Window.orderBy(ds.Score.desc())
ds = ds.withColumn('Rank_spark_dense',F.dense_rank().over(w))
ds = ds.withColumn('Rank_spark',F.rank().over(w))
ds.show()






No comments:
Post a Comment