

Introduction to Databricks
What is Databricks?
• Unified Interface
• Open analytics platform
• Compute Management
• Notebooks
• Integrates with Cloud Storages
• MLFlow modeling
• Git
• SQL Warehouses
How Databricks Work with Azure?
• Unified billing
• Integration with Data services
• Azure Entra ID (previously Azure Active Directory
• Azure Data Factory
• Power BI
• Azure DevOps
Databricks Features
- Spark as Cloud-Native Technology
- Secure Cloud Storage Integration
- ACID Transaction via Delta Lake Integration
- Unity Catalog for Meta Data Management
- Cluster Management
- Photon Query Engine
- Notebooks and Workspace
- Administration Controls
- Optimized Spark Runtime
- Automation Tools
Databricks Filesystem - DBFS
A distributed file system abstraction on top of scalable cloud storage integrated into a Databricks workspace and available on Databricks clusters.

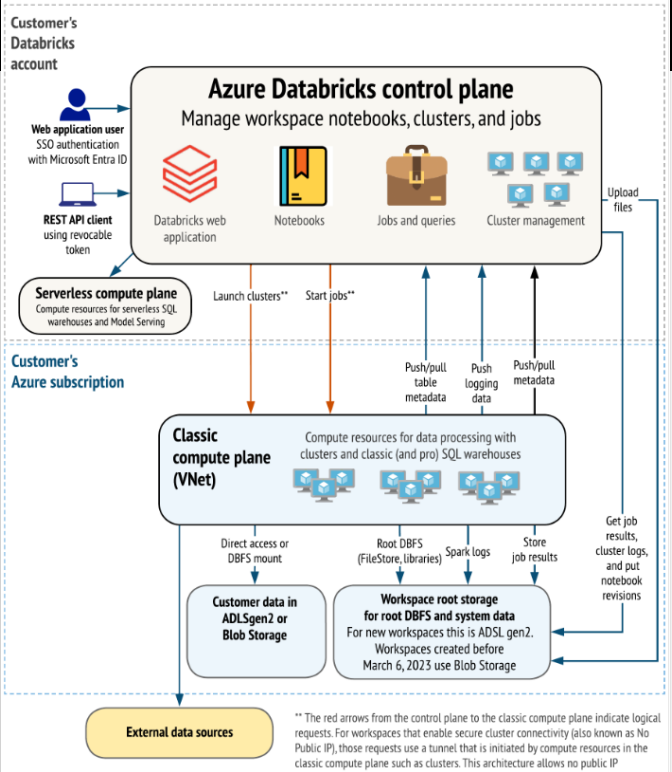
Databricks Cloud – Key Integrations



• Policies are a set of rules configured by admins
• These are used to limit the configuration options available to users
when they create a cluster
• Policies have access control lists that regulate which users and groups
have access to the policies.
• Any user with unrestricted policy can create any type of cluster
Magic commands
• You can use multiple languages in one notebook
• You need to specify language magic command at the beginning of a cell.
• By default, the entire notebook will work on the language that you choose at the top


Drawbacks of ADLS
• No ACID properties
• Job failures lead to inconsistent data
• Simultaneous writes on same folder brings incorrect results
• No schema enforcement
• No support for updates
• No support for versioning
• Data quality issues

What is Delta Lake?
- ACID transactions
- Deletes, update, and merge
- Schema enforcement and evolution
- Data versioning and Time travel
- Streaming and batch unification
- Optimizations
- Open-source storage framework that brings reliability to data lakes
- Brings transaction capabilities to data lakes
- Runs on top of your existing datalake and supports parquet
- Enables Lakehouse architecture
How to use delta lake?
Delta Lake is available as a connector






Understanding Transaction log file (Delta Log)
• Contains records of every transaction performed on the delta table
• Files under _delta_log will be stored in JSON format
• Single source of truth
Transaction log contents
• metadata – Table’s name, schema, partitioning ,etc
• Add – info of added file (with optional statistics)
• Remove – info of removed file
• Set Transaction – contains record of transaction id
• Change protocol – Contains the version that is used
• Commit info – Contains what operation was performed on this
How does schema enforcement works?
Delta lake uses Schema validation on “writes”
. Schema Enforcement Rules:
1. Cannot contain any additional columns that are not present in the target table's schema
2. Cannot have column data types that differ from the column data types in the target table.
Audit Data Changes & Time Travel
• Delta automatically versions every operation that you perform
• You can time travel to historical versions
• This versioning makes it easy to audit data changes, roll back data in case of accidental bad writes or deletes, and reproduce experiments and reports.
Using versionAsOf using PySpark Code
Using @v (VersionNumber) after Table Name
Using RESTORE command to get previous version to Table
Vacuum in Delta lake
• Vacuum helps to remove parquet files which are not in latest state in transaction log
• It will skip the files that are starting with _ (underscore) that includes _delta_log
• It deletes the files that are older then retention threshold
• Default retention threshold in 7 days
• If you run VACUUM on a Delta table, you lose the ability to time travel back to a version older than the specified data retention period.
Optimize in Delta lake

UPSERT (Merge) in delta lake
• We can UPSERT (UPDATE + INSERT) data using MERGE command.
• If any matching rows found, it will update them
• If no matching rows found, this will insert that as new row

MERGE INTO `delta`.Dest_Table AS Dest
Unity Catalog




Unity Catalog Object Model

Roles in Unity Catalog

User and Group Management
• Invite and add users to Unity Catalog
• Create groups
• Workspace admins
• Developers
• Assign groups to users
• Workspace admins – abc
• Developers - xab
• Assign roles to groups
• Workspace Admin – Workspace Admins Group
• Workspace User – Developers Group
Cluster policy
• To control user’s ability to configure clusters based on a set of rules.
• These rules specify which attributes or attribute values can be used during cluster creation.
• Cluster policies have ACLs that limit their use to specific users and groups.
• A user who has unrestricted cluster create permission can select the Unrestricted policy and create fully-configurable clusters.


• Privileges are permissions that we assign on objects to users
• Can use SQL command or Unity Catalog UI Eg:
GRANT privilege_type ON securable_object TO principal
Privilege_Type : Unity Catalog permissions like SELECT, CREATE
Securable_object: Any object like SCHEMA, TABLE , etc
Principal: Can be a user, group, etc.
Unity Catalog - Three level Namespace



• Managed Tables
• These can be defined without a specified location
• The data files are stored within managed storage in Delta format
• Dropping the table not only removes its metadata from the catalog, but also deletes the actual data but in Unity Catalog the underlying data will be present for 30 days.
• External Tables
• You need to have an EXTERNAL LOCATION and STORAGE CREDENTIALS created to access the external storage.
• These can be defined for a custom file location, other than the managed storage
• Dropping the table deletes the metadata from the catalog, but doesn't affect the data files.
Spark Structured Streaming

outputModes

Append
WriteStream = ( df.writeStream .option('checkpointLocation',f'{source_dir}/AppendCheckpoint') .outputMode("append") .queryName('AppendQuery') .toTable("stream.AppendTable"))
Complete
Triggers

Trigger - default or unspecifed Trigger
WriteStream = ( df.writeStream .option('checkpointLocation',f'{source_dir}/AppendCheckpoint') .outputMode("append") .queryName('DefaultTrigger') .toTable("stream.AppendTable"))
Trigger - processingTime
WriteStream = ( df.writeStream .option('checkpointLocation',f'{source_dir}/AppendCheckpoint') .outputMode("append") .trigger(processingTime='2 minutes') .queryName('ProcessingTime') .toTable("stream.AppendTable"))
Trigger - availablenow
WriteStream = ( df.writeStream .option('checkpointLocation',f'{source_dir}/AppendCheckpoint') .outputMode("append") .trigger(availableNow=True) .queryName('AvailableNow') .toTable("stream.AppendTable"))
Autoloader
- Cloud-native APIs
- Fewer API calls
- Incremental listing

Implementing Autoloader
df = spark.readStream\ .format('cloudFiles')\ .option("cloudFiles.format","csv")\ .option("cloudFiles.schemaLocation",f'{source_dir}/schemaInfer')\ .option("cloudFiles.inferColumnTypes","true")\ .option('header','true')\ .load(source_dir)
SchemaHints

Schema evolution
• Schema evolution is the process of managing changes in data schema
as it evolves over time, often due to updates in software or changing
business requirements, which can cause schema drift • Ways to handle schema changes• Fail the stream • Manually change the existing schema • Evolve automatically with change in schema
• addNewColumns = Stream fails. New columns are added to the schema. Existing
columns do not evolve data types. • failOnNewColumns = Stream fails. Stream does not restart unless the provided
schema is updated, or the offending data file is removed • rescue = Schema is never evolved and stream does not fail due to schema
changes. All new columns are recorded in the rescued data column. • none = ignore any new columns (Does not evolve the schema, new columns are
ignored, and data is not rescued unless the rescuedDataColumn option is set.
Stream does not fail due to schema changes.)
rescuedf = spark.readStream\ .format('cloudFiles')\ .option("cloudFiles.format","csv")\ .option("cloudFiles.schemaLocation",f'{source_dir}/schemaInfer')\ .option('cloudFiles.schemaEvolutionMode','rescue')\ .option('rescuedDataColumn','_rescued_data')\ .option("cloudFiles.inferColumnTypes","true")\ .option('cloudFiles.schemaHints',"Citizens LONG")\ .option('header','true')\ .load(source_dir)
addNewColumns - Default
df = spark.readStream\ .format('cloudFiles')\ .option("cloudFiles.format","csv")\ .option("cloudFiles.schemaLocation",f'{source_dir}/schemaInfer')\ .option("cloudFiles.inferColumnTypes","true")\ .option('cloudFiles.schemaHints',"Citizens LONG")\ .option('header','true')\ .load(source_dir)
failOnNewColumns
df = spark.readStream\ .format('cloudFiles')\ .option("cloudFiles.format","csv")\ .option("cloudFiles.schemaLocation",f'{source_dir}/schemaInfer')\ .option('cloudFiles.schemaEvolutionMode','failOnNewColumns')\ .option("cloudFiles.inferColumnTypes","true")\ .option('cloudFiles.schemaHints',"Citizens LONG")\ .option('header','true')\ .load(source_dir)
None
df = spark.readStream\ .format('cloudFiles')\ .option("cloudFiles.format","csv")\ .option("cloudFiles.schemaLocation",f'{source_dir}/schemaInfer')\ .option('cloudFiles.schemaEvolutionMode','none')\ .option("cloudFiles.inferColumnTypes","true")\ .option('cloudFiles.schemaHints',"Citizens LONG")\ .option('header','true')\ .load(source_dir)
Delta Live Tables (DLT)

Declarative programming
Declarative programming say what should be done , not how to do it

Declarative ETL with DLT
Declarative programming say what should be done , not how to do it

Delta Live Tables (DLT)
Delta Live Tables (DLT) is a declarative ETL framework for
the Databricks Data Intelligence Platform that helps data teams
simplify streaming and batch ETL cost-effectively.
Simply define the transformations to perform on your data and let DLT
pipelines automatically manage task orchestration, cluster management,
monitoring, data quality and error handling.
CREATE OR REFRESH STREAMING LIVE TABLE raw_roads_dlAS SELECT "Road ID" AS Road_ID ,"Road category id" AS Road_category_id ,"Road category" AS Road_category ,"Region id" AS Region_id,"Region name" AS Region_name,"Total link length km" AS Total_link_length_km ,"Total link length miles" AS Total_link_length_miles ,"All motor vehicles" AS All_motor_vehicles
FROM cloud_files( 'abfss://landing@databricksdevstg.dfs.core.windows.net/raw_roads', 'csv')CREATE OR REFRESH STREAMING LIVE TABLE traffic_cleaned_dl (CONSTRAINT valid_Record1 EXPECT ("Year" IS NOT NULL ) ON VIOLATION DROP ROW )AS SELECT *FROM STREAM(LIVE.`raw_traffic_dl`)
Delta Live Table Execution
• Requires premium workspace • Supports only Python and SQL languages • Can’t run interactively • No support for magic commands like %run

Continuous Integration and Continuous Deployment(CICD)

Continuous Integration

Continuous Deployment
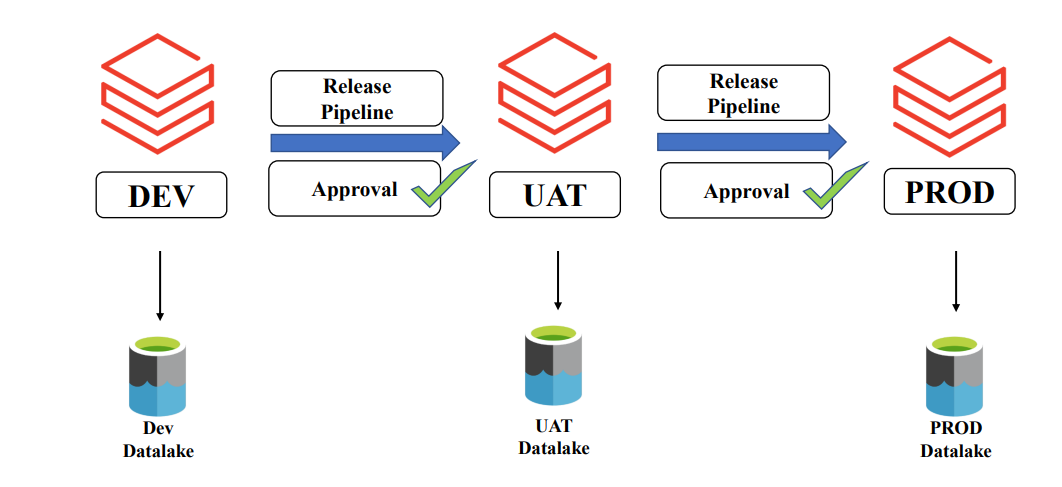 Creating UAT resources in Azure
Creating UAT resources in Azure
• Resource Group: databricks-uat-rg • Databricks workspace: databricks-uat-ws • Storage Account: databricksuatstg
cicd-main.yml
trigger: - main
variables: - group: dev-cicd-grp - name: notebookPath value: "notebooks"
pool: vmImage: "windows-latest"
stages: - template: deploy.yml parameters: stageId: "Deploy_to_Dev_Env" env: "dev" environmentName: $(dev-env-name) resourceGroupName: $(dev-resource-grp-name) serviceConnection: $(dev-service-connection-name) notebookPath: $(notebookPath)
deploy.yml
parameters: - name: stageId type: string - name: dependsOn type: object default: [] - name: env type: string - name: environmentName type: string - name: resourceGroupName type: string - name: serviceConnection type: string - name: notebookPath type: string
stages: - stage: "${{ parameters.stageId }}" displayName: "Deploying to [${{ upper(parameters.env) }}] environment" dependsOn: ${{ parameters.dependsOn }} jobs: - deployment: Deploy displayName: "Deploying Databricks Notebooks" environment: ${{ parameters.environmentName }} strategy: runOnce: deploy: steps: - checkout: self - task: AzureCLI@2 inputs: azureSubscription: ${{ parameters.serviceConnection }} scriptType: "pscore" scriptLocation: "inlineScript" inlineScript: | az config set extension.use_dynamic_install=yes_without_prompt $databricksWorkspace = (az resource list --resource-group ${{parameters.resourceGroupName}} --query "[?type =='Microsoft.Databricks/workspaces']" | ConvertFrom-Json)[0] $databricksWorkspaceInfo = (az databricks workspace show --ids $databricksWorkspace.id | ConvertFrom-Json) $bearerToken = $(Build.Repository.LocalPath)/CICD/shellScript/DBToken.ps1 -databricksWorkspaceResourceId $databricksWorkspaceInfo.id -databricksWorkspaceUrl $databricksWorkspaceInfo.workspaceUrl Install-Module -Name azure.databricks.cicd.tools -Force -Scope CurrentUser Import-Module -Name azure.databricks.cicd.tools Import-DatabricksFolder -BearerToken $bearerToken -Region $databricksWorkspaceInfo.location -LocalPath $(Build.Repository.LocalPath)/${{ parameters.notebookPath }} -DatabricksPath '/live' -Clean
DBToken.ps1
param( [parameter(Mandatory = $true)] [String] $databricksWorkspaceResourceId, [parameter(Mandatory = $true)] [String] $databricksWorkspaceUrl, [parameter(Mandatory = $false)] [int] $tokenLifeTimeSeconds = 300)
########
# Print the values for debuggingWrite-Host "Databricks Workspace Resource ID: $databricksWorkspaceResourceId"Write-Host "Databricks Workspace URL: $databricksWorkspaceUrl"
## Test on token access
# Try to get the access tokentry { $azureAccessToken = (az account get-access-token --resource https://management.azure.com | ConvertFrom-Json).accessToken Write-Host "Azure Access Token Acquired successfully."}catch { Write-Host "Failed to acquire Azure Access Token." throw $_}
########
$azureDatabricksPrincipalId = '2ff814a6-3304-4ab8-85cb-cd0e6f879c1d'
$headers = @{}$headers["Authorization"] = "Bearer $(( az account get-access-token --resource $azureDatabricksPrincipalId | ConvertFrom-Json).accessToken)"$headers["X-Databricks-Azure-SP-Management-Token"] = "$((az account get-access-token --resource https://management.core.windows.net/ | ConvertFrom-Json).accessToken)"$headers["X-Databricks-Azure-Workspace-Resource-Id"] = $databricksWorkspaceResourceId
$json = @{}$json["lifetime_seconds"] = $tokenLifeTimeSeconds
$req = Invoke-WebRequest -Uri "https://$databricksWorkspaceUrl/api/2.0/token/create" -Body ($json | ConvertTo-Json) -ContentType "application/json" -Headers $headers -Method POST$bearerToken = ($req.Content | ConvertFrom-Json).token_value
return $bearerToken
Continuous Integration

Continuous Deployment

Project Overview
Medallion Architecture




Ingesting data to Bronze Layer

Continuous Deployment
Schema: Bronze
Tables: BronzeTable
Bronze_Layer
# Reading data from store location
#Create Schemas

Silver_Layer
#Reading from bronze row layer
#calling function
df_bronze=read_bronzetable(
#write data in Silvertable
#Calling All Function

Gold_Layer
#Read Silver Layer data
#Create Load Time column
#write data in glodlayer
#Call all the function
*****************************************************************************************************************
Defining all common variables
#Removing duplicates
#Handling NULLS
Managed Identities
- You don't need to manage credentials. Credentials aren’t even accessible to you.
- You can use managed identities to authenticate to any resource that supports Microsoft Entra authentication, including your own applications.
- Managed identities can be used at no extra cost.
Managed identity types

Which operations can I perform on managed identities?
Resources that support system assigned managed identities allow you to:
- Enable or disable managed identities at the resource level.
- Use role-based access control (RBAC) to grant permissions.
- View the create, read, update, and delete (CRUD) operations in Azure Activity logs.
- View sign in activity in Microsoft Entra ID sign in logs.
If you choose a user assigned managed identity instead:
- You can create, read, update, and delete the identities.
- You can use RBAC role assignments to grant permissions.
- User assigned managed identities can be used on more than one resource.
- CRUD operations are available for review in Azure Activity logs.
- View sign in activity in Microsoft Entra ID sign in logs.
Operations on managed identities can be performed by using an Azure Resource Manager template, the Azure portal, Azure CLI, PowerShell, and REST APIs.







No comments:
Post a Comment